Quantization, Projection, and Pruning
Use Deep Learning Toolbox™ together with the Deep Learning Toolbox Model Quantization Library support package to reduce the memory footprint and computational requirements of a deep neural network by:
Pruning filters from convolution layers by using first-order Taylor approximation. You can then generate C/C++ or CUDA® code from this pruned network.
Projecting layers by performing principal component analysis (PCA) on the layer activations using a data set representative of the training data and applying linear projections on the layer learnable parameters. Forward passes of a projected deep neural network are typically faster when you deploy the network to embedded hardware using library-free C/C++ code generation.
Quantizing the weights, biases, and activations of layers to reduced precision scaled integer data types. You can then generate C/C++, CUDA, or HDL code from this quantized network.
For C/C++ and CUDA code generation, the software generates code for a convolutional deep neural network by quantizing the weights, biases, and activations of the convolution layers to 8-bit scaled integer data types. The quantization is performed by providing the calibration result file produced by the
calibratefunction to thecodegen(MATLAB Coder) command.Code generation does not support quantized deep neural networks produced by the
quantizefunction.
Functions
Apps
| Deep Network Quantizer | Quantize deep neural network to 8-bit scaled integer data types (Since R2020a) |
Topics
Pruning
- Parameter Pruning and Quantization of Image Classification Network
Use parameter pruning and quantization to reduce network size. - Prune Image Classification Network Using Taylor Scores
This example shows how to reduce the size of a deep neural network using Taylor pruning. - Prune Filters in a Detection Network Using Taylor Scores
This example shows how to reduce network size and increase inference speed by pruning convolutional filters in a you only look once (YOLO) v3 object detection network. - Prune and Quantize Convolutional Neural Network for Speech Recognition
This example shows how to compress a convolutional neural nework (CNN) to prepare it for deployment on an embedded system.
Projection and Knowledge Distillation
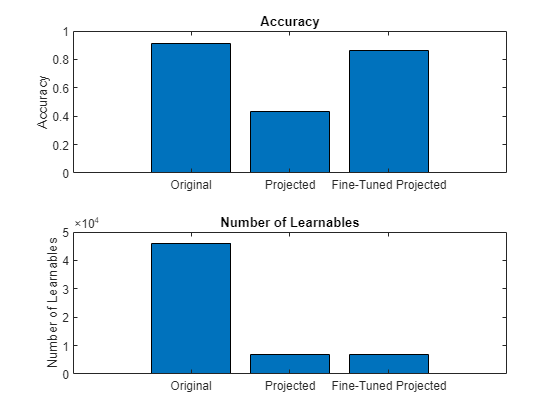
- Compress Neural Network Using Projection
This example shows how to compress a neural network using projection and principal component analysis. - Compress Network for Estimating Battery State of Charge
This example shows how to compress a neural network for predicting the state of charge of a battery using projection and principal component analysis. (Since R2023b) - Train Smaller Neural Network Using Knowledge Distillation
This example shows how to reduce the memory footprint of a deep learning network by using knowledge distillation. (Since R2023b)
Quantization
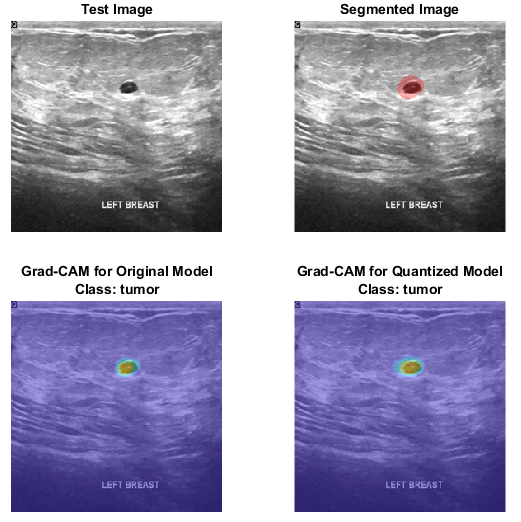
- Quantization of Deep Neural Networks
Understand effects of quantization and how to visualize dynamic ranges of network convolution layers. - Quantization Workflow Prerequisites
Products required for the quantization of deep learning networks. - Prepare Data for Quantizing Networks
Supported datastores for quantization workflows. - Quantize Multiple-Input Network Using Image and Feature Data
Quantize Multiple Input Network Using Image and Feature Data
Quantization for GPU Target
- Generate INT8 Code for Deep Learning Networks (GPU Coder)
Quantize and generate code for a pretrained convolutional neural network. - Quantize Residual Network Trained for Image Classification and Generate CUDA Code
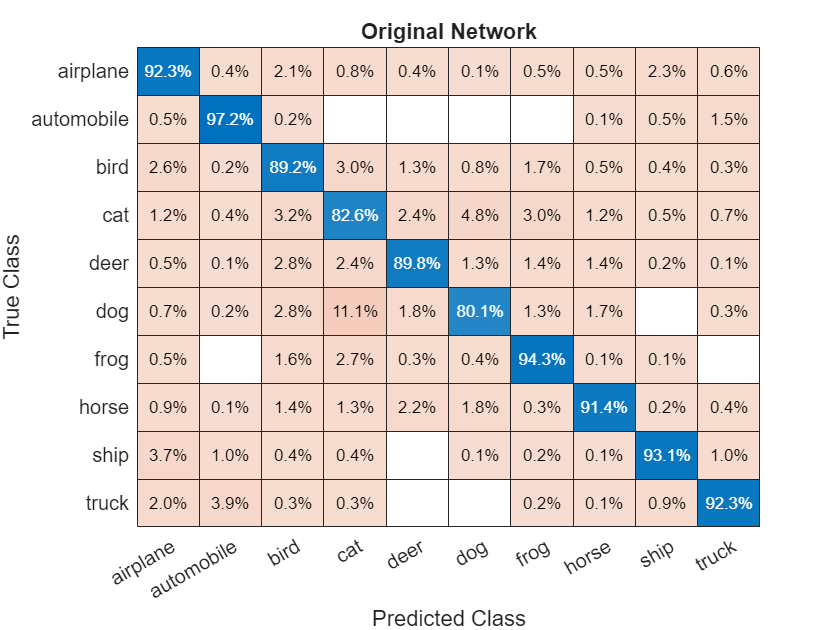
This example shows how to quantize the learnable parameters in the convolution layers of a deep learning neural network that has residual connections and has been trained for image classification with CIFAR-10 data. - Quantize Layers in Object Detectors and Generate CUDA Code
This example shows how to generate CUDA® code for an SSD vehicle detector and a YOLO v2 vehicle detector that performs inference computations in 8-bit integers for the convolutional layers. - Quantize Semantic Segmentation Network and Generate CUDA Code
Quantize Convolutional Neural Network Trained for Semantic Segmentation and Generate CUDA Code
Quantization for FPGA Target
- Quantize Network for FPGA Deployment (Deep Learning HDL Toolbox)
Reduce the memory footprint of a deep neural network by quantizing the weights, biases, and activations of convolution layers to 8-bit scaled integer data types. - Classify Images on FPGA Using Quantized Neural Network (Deep Learning HDL Toolbox)
This example shows how to use Deep Learning HDL Toolbox™ to deploy a quantized deep convolutional neural network (CNN) to an FPGA. - Classify Images on FPGA by Using Quantized GoogLeNet Network (Deep Learning HDL Toolbox)
This example show how to use the Deep Learning HDL Toolbox™ to deploy a quantized GoogleNet network to classify an image.
Quantization for CPU Target
- Generate int8 Code for Deep Learning Networks (MATLAB Coder)
Quantize and generate code for a pretrained convolutional neural network. - Generate INT8 Code for Deep Learning Network on Raspberry Pi (MATLAB Coder)
Generate code for deep learning network that performs inference computations in 8-bit integers.
Featured Examples



You can also select a web site from the following list:
Americas
- América Latina (Español)
- Canada (English)
- United States (English)
Europe
- Belgium (English)
- Denmark (English)
- Deutschland (Deutsch)
- España (Español)
- Finland (English)
- France (Français)
- Ireland (English)
- Italia (Italiano)
- Luxembourg (English)
- Netherlands (English)
- Norway (English)
- Österreich (Deutsch)
- Portugal (English)
- Sweden (English)
- Switzerland
- United Kingdom (English)