GPU Profiling on NVIDIA Jetson Platforms
This example shows you how to analyze and optimize the performance of the generated CUDA® code on the Jetson™ platform by using the gpuPerformanceAnalyzer function.
The gpuPerformanceAnalyzer function runs a software-in-the-loop (SIL) execution that collects metrics on CPU and GPU activities in the generated code. The function provides a report containing a chronological timeline plot that you can use to visualize, identify, and mitigate performance bottlenecks in the generated CUDA code.
This example generates the performance analyzer report for the Feature Matching example from GPU Coder™. For more information, see Feature Matching.
Prerequisites
Target Board Requirements
NVIDIA® Jetson™ embedded platform.
Ethernet crossover cable to connect the target board and host PC (if the target board cannot be connected to a local network).
NVIDIA CUDA toolkit installed on the target board.
Environment variables on the target for the compilers and libraries. For information on the supported versions of the compilers and libraries and their setup, see Install and Setup Prerequisites for NVIDIA Boards for NVIDIA boards.
Permissions to access GPU performance counters. From CUDA toolkit v10.1, NVIDIA restricts access to performance counters to only admin users. To enable GPU performance counters to for all users, see the instructions provided in Permission issue with Performance Counters (NVIDIA).
Development Host Requirements
NVIDIA CUDA toolkit and driver.
Environment variables for the compilers and libraries. For information on the supported versions of the compilers and libraries, see Third-Party Hardware. For setting up the environment variables, see Setting Up the Prerequisite Products.
Verify NVIDIA Support Package Installation on Host
Use the checkHardwareSupportPackageInstall function to verify that the host system has the necessary support packages to run this example.
checkHardwareSupportPackageInstall();
Connect to the NVIDIA Hardware
The GPU Coder Support Package for NVIDIA GPUs uses an SSH connection over TCP/IP to execute commands while building and running the generated CUDA code on the Jetson platform. You must therefore connect the target platform to the same network as the host computer or use an Ethernet crossover cable to connect the board directly to the host computer. Refer to the NVIDIA documentation on how to set up and configure your board.
To communicate with the NVIDIA hardware, you must create a live hardware connection object by using the jetson function. You must know the host name or IP address, username, and password of the target board to create a live hardware connection object. For example, when connecting to the target board for the first time, create a live object for Jetson hardware by using the command:
hwobj= jetson('host-name','username','password');
The jetson object reuses these settings from the most recent successful connection to the Jetson hardware. This example establishes an SSH connection to the Jetson hardware using the settings stored in memory.
hwobj = jetson;
Checking for CUDA availability on the Target... Checking for 'nvcc' in the target system path... Checking for cuDNN library availability on the Target... Checking for TensorRT library availability on the Target... Checking for prerequisite libraries is complete. Gathering hardware details... Checking for third-party library availability on the Target... Gathering hardware details is complete. Board name : NVIDIA Jetson AGX Xavier Developer Kit CUDA Version : 11.4 cuDNN Version : 8.4 TensorRT Version : 8.4 GStreamer Version : 1.16.3 V4L2 Version : 1.18.0-2build1 SDL Version : 1.2 OpenCV Version : 4.5.4 Available Webcams : Logitech Webcam C925e Available GPUs : Xavier Available Digital Pins : 7 11 12 13 15 16 18 19 21 22 23 24 26 29 31 32 33 35 36 37 38 40
In case of a connection failure, a diagnostics error message is reported on the MATLAB® command line. If the connection has failed, the most likely cause is incorrect IP address or hostname.
When there are multiple live connection objects for different targets, the code generator performs remote build on the target for which a recent live object was created. To choose a hardware board for performing remote build, use the setupCodegenContext() method of the respective live hardware object. If only one live connection object was created, it is not necessary to call this method.
hwobj.setupCodegenContext;
Verify GPU Environment on the Target
To verify that the compilers and libraries necessary for this example are set up correctly, use the coder.checkGpuInstall function.
envCfg = coder.gpuEnvConfig('jetson'); envCfg.DeepLibTarget = 'cudnn'; envCfg.DeepCodegen = 1; envCfg.Quiet = 1; envCfg.HardwareObject = hwobj; coder.checkGpuInstall(envCfg);
When the Quiet property of the coder.gpuEnvConfig object is set to true, the coder.checkGpuInstall function returns only warning or error messages.
Feature Detection and Extraction
For this example, feature matching is performed on two images that are rotated and scaled with respect to each other. Before the two images can be matched, feature points for each image must be detected and extracted. The following featureDetectionAndExtraction function uses SURF (detectSURFFeatures (Computer Vision Toolbox)) local feature detector to detect the feature points and extractFeatures (Computer Vision Toolbox) to extract the features.
The function featureDetectionAndExtraction returns refPoints, which contains the feature coordinates of the reference image, qryPoints, containing feature coordinates of query image, refDesc matrix containing reference image feature descriptors and qryDesc matrix containing query image feature descriptors.
refPoints = Reference image feature coordinates.
qryPoints = Query image feature coordinates.
refDescFeat = Reference image feature descriptors.
qryDescFeat = Query image feature descriptors.
K = imread('cameraman.tif'); refImage = imresize(K,3); scale = 0.7; J = imresize(refImage,scale); theta = 30.0; qryImage = imrotate(J,theta); [refPoints,refDescFeat,qryPoints,qryDescFeat] = featureDetectionAndExtraction(refImage,... qryImage);
The feature_matching Entry-Point Function
The feature_matching function takes feature points and feature descriptors extracted from two images and finds a match between them.
type feature_matchingfunction [matchedRefPoints,matchedQryPoints] = feature_matching(refPoints,...
refDesc,qryPoints,qryDesc)
%#codegen
% Copyright 2018-2021 The MathWorks, Inc.
coder.gpu.kernelfun;
%% Feature Matching
[indexPairs,matchMetric] = matchFeatures(refDesc, qryDesc);
matchedRefPoints = refPoints(indexPairs(:,1),:);
matchedQryPoints = qryPoints(indexPairs(:,2),:);
Generate GPU Performance Analyzer Report
To analyze the performance of the generated code by using the gpuPerformanceAnalyzer function, create a code configuration object with a dynamic library build type by using the dll input argument. Enable the option to create a coder.EmbeddedCodeConfig configuration object.
cfg = coder.gpuConfig('dll','ecoder',true);
You can also use GPU performance analyzer to profile deep learning applications and embedded applications targeting NVIDIA® Jetson™ and NVIDIA DRIVE® platforms. To use gpuPerformanceAnalyzer for embedded targets, set the hardware property of the code configuration object to the appropriate target platform.
cfg.Hardware = coder.Hardware('NVIDIA Jetson');Run gpuPerformanceAnalyzer with the default iteration count of 2.
inputs = {refPoints,refDescFeat,qryPoints,qryDescFeat};
designFileName = 'feature_matching';
gpuPerformanceAnalyzer(designFileName, inputs, ...
'Config', cfg, 'NumIterations', 2);Checking for CUDA availability on the Target...
Checking for 'nvcc' in the target system path...
### Starting GPU code generation
### Connectivity configuration for function 'feature_matching': 'NVIDIA Jetson'
PIL execution is using Port 17725.
PIL execution is using 30 Sec(s) for receive time-out.
Code generation successful: View report
### GPU code generation finished
### Starting application profiling
### Starting application: 'codegen/dll/feature_matching/pil/feature_matching.elf'
To terminate execution: clear feature_matching_pil
### Launching application feature_matching.elf...
PIL execution terminated on target.
### Application profiling finished
### Starting profiling data processing
### Profiling data processing finished
### Showing profiling data
GPU Performance Analyzer
The GPU performance analyzer report lists GPU and CPU activities, events, and performance metrics in a chronological timeline plot that you can use to visualize, identify, and address performance bottlenecks in the generated CUDA code.

These numbers are representative. The actual values depend on your hardware setup. The profiling in this example was performed using MATLAB® R2023b on a machine with an 6 core, 3.5GHz Intel® Xeon® CPU, and an NVIDIA TITAN XP GPU and a Jetson AGX Xavier development kit.
Profiling Timeline
The profiling timeline shows the complete trace of all events that have a runtime higher than the threshold value. This image shows a snippet of the profiling trace when the threshold value is set to 0.0 ms.
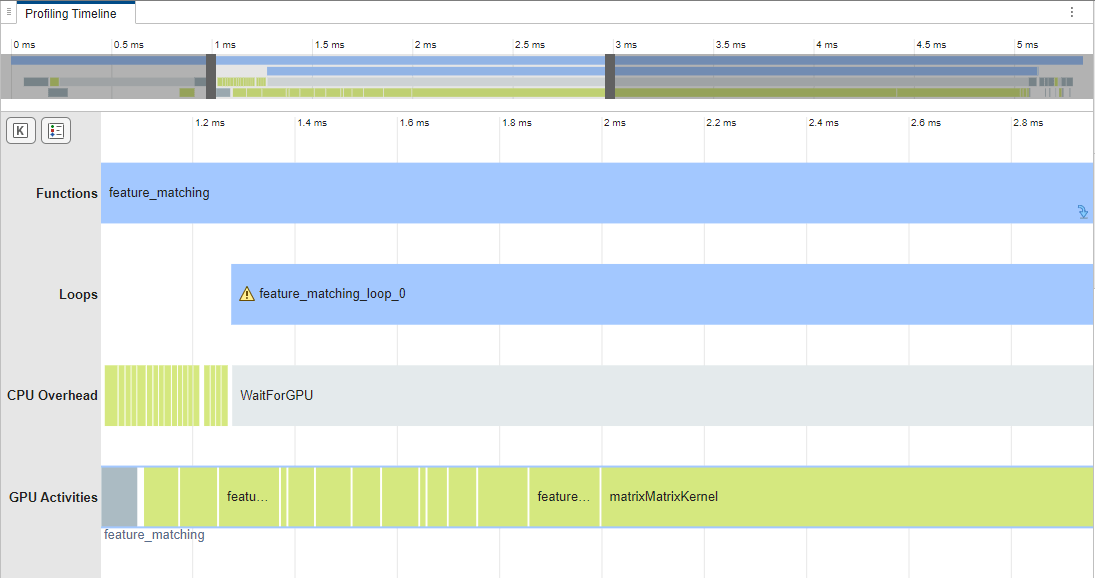
You can use the mouse wheel or the equivalent touchpad option to control the zoom level of the timeline. Alternatively, you can use the timeline summary at the top of the panel to control the zoom level and navigate the timeline plot.
The tooltips on each event indicate the start time, end time, and duration of the selected event on the CPU and the GPU. The tooltips also indicate the time elapsed between the kernel launch on the CPU and the actual execution of the kernel on the GPU.
Use the right-click context menu on each event to add a trace between the CPU and corresponding GPU events. You can also use the right-click menu to view the generated CUDA code that corresponds to an event on the code pane.
Event statistics
The event statistics pane shows additional information for the selected event. For example, the feature_matching_kernel1 shows the following statistics:

Insights
The insights pane includes pie charts that provide an overview of the GPU and CPU activities. The pie chart changes according to the zoom level of the profiling timeline. This image shows a snippet of the insights.Within the region selected on the timeline, it shows that the GPU utilization is only 52%.

Call Tree
This section lists the GPU events called from the CPU. Each event in the call tree lists the execution times as percentages of the caller function. This metric can help you to identify performance bottlenecks in the generated code. You can also navigate to specific events on the profiling timeline by clicking on the corresponding events in the call tree.
Filters
This section provides filtering options for the report.
View Mode — View profiling results for the entire application, including initialization and terminate, or the design function (without initialization and terminate).
Event Threshold — Skip events shorter than the given threshold.
Memory Allocation/Free — Show GPU device memory allocation and deallocation related events on the CPU activities bar.
Memory Transfers — Show host-to-device and device-to-host memory transfers.
Kernels — Show CPU kernel launches and GPU kernel activities.
Others — Show other GPU related events such as synchronization and waiting for GPU.
Improving the Performance of the Feature_Matching
From the performance analyzer report, you can observe that a significant portion of the execution time is spent on memory allocation and deallocation. To improve the performance, turn on GPU memory manager and run the analysis again.
The GPU memory manager creates a collection of large GPU memory pools and manages the allocation and deallocation of chunks of memory blocks within these pools. By creating large memory pools, the memory manager reduces the number of calls to the CUDA memory APIs and improves run-time performance.
killApplication(hwobj,'feature_matching'); cfg = coder.gpuConfig('dll'); cfg.GpuConfig.EnableMemoryManager = true; cfg.Hardware = coder.Hardware('NVIDIA Jetson'); gpuPerformanceAnalyzer(designFileName, inputs, ... 'Config', cfg, 'NumIterations', 2);
Checking for CUDA availability on the Target...
Checking for 'nvcc' in the target system path...
### Starting GPU code generation
### Connectivity configuration for function 'feature_matching': 'NVIDIA Jetson'
PIL execution is using Port 17725.
PIL execution is using 30 Sec(s) for receive time-out.
Code generation successful: View report
### GPU code generation finished
### Starting application profiling
### Starting application: 'codegen/dll/feature_matching/pil/feature_matching.elf'
To terminate execution: clear feature_matching_pil
### Launching application feature_matching.elf...
PIL execution terminated on target.
### Application profiling finished
### Starting profiling data processing
### Profiling data processing finished
### Showing profiling data
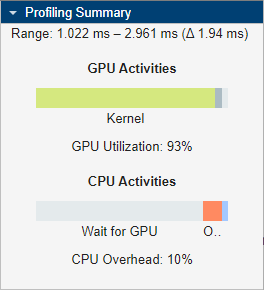
With GPU memory manager, the GPU utilization has increased to 76%.
See Also
Functions
Objects
Related Topics
You can also select a web site from the following list:
Americas
- América Latina (Español)
- Canada (English)
- United States (English)
Europe
- Belgium (English)
- Denmark (English)
- Deutschland (Deutsch)
- España (Español)
- Finland (English)
- France (Français)
- Ireland (English)
- Italia (Italiano)
- Luxembourg (English)
- Netherlands (English)
- Norway (English)
- Österreich (Deutsch)
- Portugal (English)
- Sweden (English)
- Switzerland
- United Kingdom (English)