Design Patterns
GPU Coder™ supports some design patterns that map efficiently to GPU structures.
Stencil Processing
Stencil kernel operations compute each element of the output array as a function of a small region of the input array. You can express many filtering operations as a stencil operation. Examples include convolution, median filtering, and finite element methods.
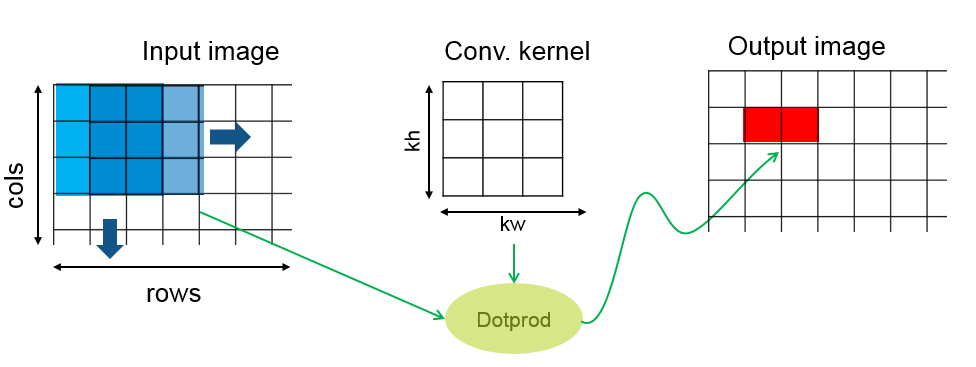
In the GPU Coder implementation of the stencil kernel, each thread computes one element of the output array. Because a given input element is accessed repeatedly for computing multiple neighboring output elements, GPU Coder uses shared memory to improve memory bandwidth and data locality.
Use the stencilfun
function and create CUDA® code for stencil functions. For an example that demonstrates stencil
preprocessing, see Stencil Processing on GPU.
Note
Starting in R2022b, generate CUDA kernels for stencil like operations by using stencilfun
function. gpucoder.stencilKernel is not recommended.
For very large input sizes, the stencilfun
function may produce CUDA code that does not numerically match the MATLAB® simulation. In such cases, consider reducing the size of the input to produce
accurate results.
Matrix-Matrix Processing
Many scientific applications contain matrix-matrix operations including the GEneral
Matrix to Matrix Multiplication (GEMM), of the form C = AB where you can
optionally transpose A and B. The code for such
matrix-matrix operations typically takes the pattern:
for x = 1:M for y = 1:N for z = 1:K C(x,y) = F(A(x,z),B(z,y)); end end end
where F() is a user-defined function. In these operations, a row from
one input matrix and a column from the second input matrix is used to compute the
corresponding element of the output matrix. Every thread reloads the row and column. This
design pattern allows optimization of this structure by reusing data and making each thread
compute multiple output elements.
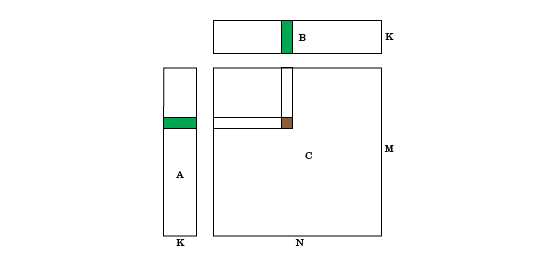
For example, F() can be a regular matrix multiply,
F()=@mtimes. For such patterns, GPU Coder provides the MatrixMatrix kernel to create a highly
efficient, fast implementation of matrix-matrix operations on the GPU.
Use the gpucoder.matrixMatrixKernel function and create CUDA code for performing matrix-matrix type operations.
See Also
coder.gpu.kernel | coder.gpu.kernelfun | gpucoder.matrixMatrixKernel | coder.gpu.constantMemory | gpucoder.stencilKernel
Related Examples
More About
You can also select a web site from the following list:
Americas
- América Latina (Español)
- Canada (English)
- United States (English)
Europe
- Belgium (English)
- Denmark (English)
- Deutschland (Deutsch)
- España (Español)
- Finland (English)
- France (Français)
- Ireland (English)
- Italia (Italiano)
- Luxembourg (English)
- Netherlands (English)
- Norway (English)
- Österreich (Deutsch)
- Portugal (English)
- Sweden (English)
- Switzerland
- United Kingdom (English)