Benchmark Your Cluster with the HPC Challenge
This example shows how to evaluate the performance of a compute cluster with the HPC Challenge Benchmark. The benchmark consists of several tests that measure different memory access patterns. For more information, see HPC Challenge Benchmark.
Prepare the HPC Challenge
Start a parallel pool of workers in your cluster using the parpool function. By default, parpool creates a parallel pool using your default cluster profile. Check your default cluster profile on the Home tab, in Parallel > Select a Default Cluster. In this benchmark, the workers communicate with each other. To ensure that interworker communication is optimized, set 'SpmdEnabled' to true.
pool = parpool(64,'SpmdEnabled',true);Starting parallel pool (parpool) using the 'MyCluster' profile ... Connected to parallel pool with 64 workers.
Use the hpccDataSizes function to compute a problem size for each individual benchmark that fulfils the requirements of the HPC Challenge. This size depends on the number of workers and the amount of memory available to each worker. For example, allow use of 1 GB per worker.
gbPerWorker = 1; dataSizes = hpccDataSizes(pool.NumWorkers,gbPerWorker);
Run the HPC Challenge
The HPC Challenge benchmark consists of several pieces, each of which explores the performance of different aspects of the system. In the following code, each function runs a single benchmark, and returns a row table that contains performance results. These functions test a variety of operations on distributed arrays. MATLAB partitions distributed arrays across multiple parallel workers, so they can use the combined memory and computational resources of your cluster. For more information on distributed arrays, see Distributed Arrays.
HPL
hpccHPL(m), known as the Linpack Benchmark, measures the execution rate for solving a linear system of equations. It creates a random distributed real matrix A of size m-by-m and a real random distributed vector b of length m, and measures the time to solve the system x = A\b in parallel. The performance is returned in gigaflops (billions of floating-point operations per second).
hplResult = hpccHPL(dataSizes.HPL);
Starting HPCC benchmark: HPL with data size: 27.8255 GB. Running on a pool of 64 workers Analyzing and transferring files to the workers ...done. Finished HPCC benchmark: HPL in 196.816 seconds.
DGEMM
hpccDGEMM(m) measures the execution rate of real matrix-matrix multiplication. It creates random distributed real matrices A, B, and C, of size m-by-m, and measures the time to perform the matrix multiplication C = beta*C + alpha*A*B in parallel, where alpha and beta are random scalars. The performance is returned in gigaflops.
dgemmResult = hpccDGEMM(dataSizes.DGEMM);
Starting HPCC benchmark: DGEMM with data size: 9.27515 GB. Running on a pool of 64 workers Analyzing and transferring files to the workers ...done. Finished HPCC benchmark: DGEMM in 69.3654 seconds.
STREAM
hpccSTREAM(m) assesses the memory bandwidth of the cluster. It creates random distributed vectors b and c of length m, and a random scalar k, and computes a = b + c*k. This benchmark does not use interworker communication. The performance is returned in gigabytes per second.
streamResult = hpccSTREAM(dataSizes.STREAM);
Starting HPCC benchmark: STREAM with data size: 10.6667 GB. Running on a pool of 64 workers Analyzing and transferring files to the workers ...done. Finished HPCC benchmark: STREAM in 0.0796962 seconds.
PTRANS
hpccPTRANS(m) measures the interprocess communication speed of the system. It creates two random distributed matrices A and B of size m-by-m, and computes A' + B. The result is returned in gigabytes per second.
ptransResult = hpccPTRANS(dataSizes.PTRANS);
Starting HPCC benchmark: PTRANS with data size: 9.27515 GB. Running on a pool of 64 workers Analyzing and transferring files to the workers ...done. Finished HPCC benchmark: PTRANS in 6.43994 seconds.
RandomAccess
hpccRandomAccess(m) measures the number of memory locations in a distributed vector that can be randomly updated per second. The result is retuned in GUPS, giga updates per second. In this test, the workers use a random number generator compiled into a MEX function. Attach a version of this MEX function for each operating system architecture to the parallel pool, so the workers can access the one that corresponds to their operating system.
addAttachedFiles(pool,{'hpccRandomNumberGeneratorKernel.mexa64','hpccRandomNumberGeneratorKernel.mexw64','hpccRandomNumberGeneratorKernel.mexmaci64'});
randomAccessResult = hpccRandomAccess(dataSizes.RandomAccess);Starting HPCC benchmark: RandomAccess with data size: 16 GB. Running on a pool of 64 workers Analyzing and transferring files to the workers ...done. Finished HPCC benchmark: RandomAccess in 208.103 seconds.
FFT
hpccFFT(m) measures the execution rate of a parallel fast Fourier transform (FFT) computation on a distributed vector of length m. This test measures both the arithmetic capability of the system and the communication performance. The performance is returned in gigaflops.
fftResult = hpccFFT(dataSizes.FFT);
Starting HPCC benchmark: FFT with data size: 8 GB. Running on a pool of 64 workers Analyzing and transferring files to the workers ...done. Finished HPCC benchmark: FFT in 11.772 seconds.
Display the Results
Each benchmark results in a single table row with statistics. Concatenate these rows to provide a summary of the test results.
allResults = [hplResult; dgemmResult; streamResult; ...
ptransResult; randomAccessResult; fftResult];
disp(allResults); Benchmark DataSizeGB Time Performance PerformanceUnits
______________ __________ ________ ___________ ________________
"HPL" 27.826 196.82 773.11 "GFlops"
"DGEMM" 9.2752 69.365 1266.4 "GFlops"
"STREAM" 10.667 0.079696 431.13 "GBperSec"
"PTRANS" 9.2752 6.4399 1.5465 "GBperSec"
"RandomAccess" 16 208.1 0.010319 "GUPS"
"FFT" 8 11.772 6.6129 "GFlops"
Offload Computations with batch
You can use the batch function to offload the computations in the HPC Challenge to your cluster and continue working in MATLAB.
Before using batch, delete the current parallel pool. A batch job cannot be processed if a parallel pool is already using all available workers.
delete(gcp);
Send the function hpccBenchmark as a batch job to the cluster by using batch. This function invokes the tests in the HPC Challenge and returns the results in a table. When you use batch, a worker takes the role of the MATLAB client and executes the function. In addition, specify these name-value pair arguments:
'Pool': Creates a parallel pool with workers for the job. In this case, specify32workers.hpccBenchmarkruns the HPC Challenge on those workers.'AttachedFiles':Transfers files to the workers in the pool. In this case, attach a version of thehpccRandomNumberGeneratorKernelfor each operating system architecture. The workers access the one that corresponds to their operating system when they execute thehpccRandomAccesstest.'CurrentFolder': Sets the working directory of the workers. If you do not specify this argument, MATLAB changes the current directory of the workers to the current directory in the MATLAB client. Set it to'.'if you want to use the current folder of the workers instead. This is useful when the workers have a different file system.
gbPerWorker = 1;
job = batch(@hpccBenchmark,1,{gbPerWorker}, ...
'Pool',32, ...
'AttachedFiles',{'hpccRandomNumberGeneratorKernel.mexa64','hpccRandomNumberGeneratorKernel.mexw64','hpccRandomNumberGeneratorKernel.mexmaci64'}, ...
'CurrentFolder','.');After you submit the job, you can continue working in MATLAB. You can check the state of the job by using the Job Monitor. On the Home tab, in the Environment area, select Parallel > Monitor Jobs.
In this case, wait for the job to finish. To retrieve the results back from the cluster, use the fetchOutputs function.
wait(job);
results = fetchOutputs(job);
disp(results{1}) Benchmark DataSizeGB Time Performance PerformanceUnits
______________ __________ ________ ___________ ________________
"HPL" 13.913 113.34 474.69 "GFlops"
"DGEMM" 4.6376 41.915 740.99 "GFlops"
"STREAM" 5.3333 0.074617 230.24 "GBperSec"
"PTRANS" 4.6376 3.7058 1.3437 "GBperSec"
"RandomAccess" 8 189.05 0.0056796 "GUPS"
"FFT" 4 7.6457 4.9153 "GFlops"
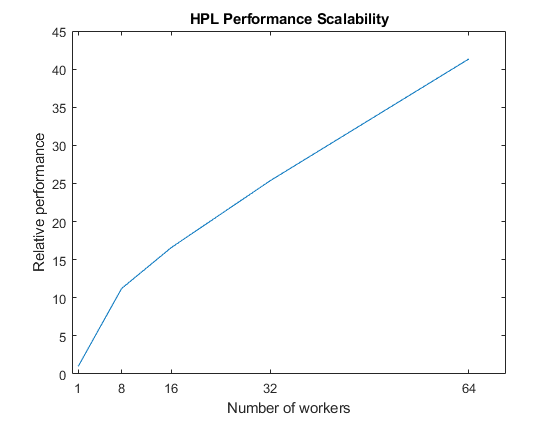
When you use large clusters, you increase the available computational resources. If the time spent on calculations outweighs the time spent on interworker communication, then your problem can scale up well. The following figure shows the scaling of the HPL benchmark with the number of workers, on a cluster with 4 machines and 18 physical cores per machine. Note that in this benchmark, the size of the data increases with the number of workers.
See Also
Related Topics
You can also select a web site from the following list:
Americas
- América Latina (Español)
- Canada (English)
- United States (English)
Europe
- Belgium (English)
- Denmark (English)
- Deutschland (Deutsch)
- España (Español)
- Finland (English)
- France (Français)
- Ireland (English)
- Italia (Italiano)
- Luxembourg (English)
- Netherlands (English)
- Norway (English)
- Österreich (Deutsch)
- Portugal (English)
- Sweden (English)
- Switzerland
- United Kingdom (English)